deberta|deberta tokenizer : Clark DeBERTa is a model that improves BERT and RoBERTa using disentangled attention and enhanced mask decoder. It outperforms them on many NLU tasks with 80GB data. See .
Manoela Fernandez. HD 13530 2 min. Lairssa manoela. Videos porno de Larissa manoela mostrando a buceta disponiveis na internet. O maior site de porno gratis. Todos os filmes porno de Larissa manoela mostrando a buceta estão no porno26.com.
0 · deberta模型
1 · deberta vs roberta
2 · deberta tokenizer
3 · deberta model pdf
4 · deberta model explained
5 · deberta model
6 · deberta explained
7 · deberta chinese
8 · More
WEBUm dos mais badalados spots do Rio de Janeiro, o Boteco Boa Praça chega em Brasília. A 9ª unidade da marca, já presente em São Paulo, Rio de Janeiro, Niterói, Vitória e Curitiba, abre as portas ao público nesta quarta-feira, 25, na comercial da 201 Sul, e é a primeira do Centro-Oeste.A casa faz parte do Grupo Alfie Nino, que conta com .
deberta*******DeBERTa is a language model that improves BERT and RoBERTa using disentangled attention and mask decoder. The repository contains the official i.
DeBERTa Overview. The DeBERTa model was proposed in DeBERTa: Decoding-enhanced BERT with Disentangled Attention by Pengcheng He, Xiaodong Liu, Jianfeng .DeBERTaV3 is a state-of-the-art natural language processing model that improves DeBERTa using ELECTRA-style pre-training and gradient disentangled embedding .deberta deberta tokenizerDeBERTa is a neural language model that improves BERT and RoBERTa with a disentangled attention mechanism and an enhanced mask decoder. It also uses a virtual .deberta tokenizerDeBERTa is a pre-trained neural language model that improves BERT and RoBERTa using two novel techniques: disentangled attention and enhanced mask decoder. It achieves .DeBERTa is a model that improves BERT and RoBERTa using disentangled attention and enhanced mask decoder. It outperforms them on many NLU tasks with 80GB data. See .DeBERTa is an innovative language model that enhances the capabilities of BERT by introducing Decoding-enhanced mechanisms with Disentangled Attention. Unlike .deberta DeBERTa is a transformer model that improves BERT and RoBERTa with disentangled attention and enhanced mask decoder. Learn how DeBERTa works, its features, and its performance on NLP tasks .DeBERTa is a large scale pre-trained language models which surpass T5 11B models with 1.5 parameters and achieve human performance on SuperGLUE. microsoft/DeBERTa: .
Nevertheless, new ideas and approaches evolve regularly in the machine learning world. One of the most innovative techniques in BERT-like models appeared in 2021 and introduced an enhanced attention version called “Disentangled attention”.The implementation of this concept gave rise to DeBERTa — the model incorporating . DeBERTa (Decoding-enhanced BERT with disentangled attention) improves the BERT and RoBERTa models using two novel techniques. The first is the disentangled attention mechanism, where .
DeBERTa (Decoding-enhanced BERT with disentangled attention) improves the BERT and RoBERTa models using two novel techniques. The first is the disentangled attention mechanism, where each word is represented using two vectors that encode its content and position, respectively, and the attention weights among words are computed .
The significant performance boost makes the single DeBERTa model surpass the human performance on the SuperGLUE benchmark (Wang et al., 2019a) for the first time in terms of macro-average score (89.9 versus 89.8), and the ensemble DeBERTa model sits atop the SuperGLUE leaderboard as of January 6, 2021, out performing the human baseline .
deberta-base. DeBERTa improves the BERT and RoBERTa models using disentangled attention and enhanced mask decoder. It outperforms BERT and RoBERTa on majority of NLU tasks with 80GB training data. Please check the official repository for more details and updates. We present the dev results on SQuAD 1.1/2.0 and MNLI tasks.
The DeBERTa V3 large model comes with 24 layers and a hidden size of 1024. It has 304M backbone parameters with a vocabulary containing 128K tokens which introduces 131M parameters in the Embedding layer. This model was trained using the 160GB data as DeBERTa V2. We present the dev results on SQuAD 2.0 and MNLI tasks. A new model architecture DeBERTa (Decoding-enhanced BERT with disentangled attention) is proposed that improves the BERT and RoBERTa models using two novel techniques that significantly improve the efficiency of model pre-training and performance of downstream tasks. Recent progress in pre-trained neural language .Welcome to DeBERTa’s documentation!¶ Contents: DeBERTa. DeBERTa Model; NNModule; DisentangledSelfAttention; ContextPoolermDeBERTa is multilingual version of DeBERTa which use the same structure as DeBERTa and was trained with CC100 multilingual data. The mDeBERTa V3 base model comes with 12 layers and a hidden size of 768. It has 86M backbone parameters with a vocabulary containing 250K tokens which introduces 190M parameters in the Embedding layer.Overview¶. The DeBERTa model was proposed in DeBERTa: Decoding-enhanced BERT with Disentangled Attention by Pengcheng He, Xiaodong Liu, Jianfeng Gao, Weizhu Chen It is based on Google’s BERT model released in 2018 and Facebook’s RoBERTa model released in 2019.. It builds on RoBERTa with disentangled attention and enhanced mask .DeBERTa Overview The DeBERTa model was proposed in DeBERTa: Decoding-enhanced BERT with Disentangled Attention by Pengcheng He, Xiaodong Liu, Jianfeng Gao, Weizhu Chen It is based on Google’s BERT model released in 2018 and Facebook’s RoBERTa model released in 2019.. It builds on RoBERTa with disentangled attention and .
DeBERTa is pre-trained for one million steps with 2K samples in each step. This amounts to two billion training samples, approximately half of either RoBERTa or XLNet. Table 1 shows that compared to BERT and RoBERTa, DeBERTa performs consistently better across all the tasks. Meanwhile, DeBERTa outperforms XLNet in six out of eight tasks.
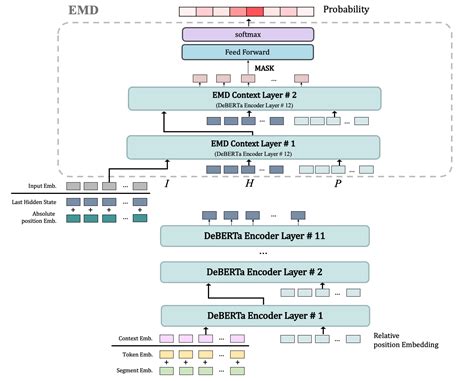
DeBERTa Overview. The DeBERTa model was proposed in DeBERTa: Decoding-enhanced BERT with Disentangled Attention by Pengcheng He, Xiaodong Liu, Jianfeng Gao, Weizhu Chen It is based on Google’s BERT model released in 2018 and Facebook’s RoBERTa model released in 2019.. It builds on RoBERTa with disentangled attention .The DeBERTa V3 small model comes with 6 layers and a hidden size of 768. It has 44M backbone parameters with a vocabulary containing 128K tokens which introduces 98M parameters in the Embedding layer. This model was trained using the 160GB data as DeBERTa V2. We present the dev results on SQuAD 2.0 and MNLI tasks. DeBERTa 模型使用了两种新技术改进了 BERT 和 RoBERTa 模型,同时还引入了一种新的微调方法以提高模型的泛化能力。 两种新技术的改进: 注意力解耦机制 :图1右侧黄色部分 This repository is the official implementation of DeBERTa: Decoding-enhanced BERT with Disentangled Attention and DeBERTa V3: Improving DeBERTa using ELECTRA-Style Pre-Training with Gradient-Disentangled Embedding Sharing Recent progress in pre-trained neural language models has significantly improved the performance of many natural language processing (NLP) tasks. In this paper we propose a new model architecture DeBERTa (Decoding-enhanced BERT with disentangled attention) that improves the BERT and RoBERTa models using two novel .The bare DeBERTa Model transformer outputting raw hidden-states without any specific head on top. The DeBERTa model was proposed in DeBERTa: Decoding-enhanced BERT with Disentangled Attention by Pengcheng He, Xiaodong Liu, Jianfeng Gao, Weizhu Chen. It’s build on top of BERT/RoBERTa with two improvements, i.e. disentangled attention .
DeBERTa (Decoding-enhanced BERT with disentangled attention) improves the BERT and RoBERTa models using two novel techniques. The first is the disentangled attention mechanism, where each word is represented using two vectors that encode its content and position, respectively, and the attention weights among words .per we propose a new model architecture DeBERTa (Decoding-enhanced BERT with disentangled attention) that improves the BERT and RoBERTa models using two novel techniques. The first is the disentangled attention mechanism, where each word is represented using two vectors that encode its content and position,DeBERTa improves the BERT and RoBERTa models using disentangled attention and enhanced mask decoder. With those two improvements, DeBERTa out perform RoBERTa on a majority of NLU tasks with 80GB training data. In DeBERTa V3, we further improved the efficiency of DeBERTa using ELECTRA-Style pre-training with Gradient .DeBERTa is a large scale pre-trained language models which surpass T5 11B models with 1.5 parameters and achieve human performance on SuperGLUE.
The latest tweets from @_minigabys
deberta|deberta tokenizer